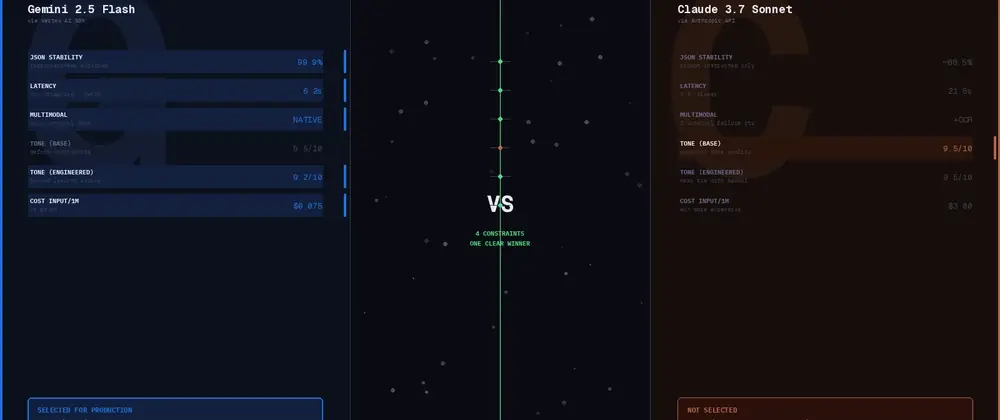
The release of GPT-5.4 is not just another incremental update to LLM; is a stark reminder of a fundamental blind spot in our observability stacks. While the headlines focus on new capabilities, we are seeing the industry grapple with a more insidious problem: latent behavioral drift in user interfaces, caused by subtle, seamless changes to complex backend systems.
Your application is not just a collection of APIs; It is a dynamic and interactive experience. And that experience is increasingly fragile.
The illusion of semantic stability
Consider the typical lifecycle of an LLM integration:
- Initial integration: its interface components are meticulously designed to analyze, display and interact with specific semantic patterns and response structures of an LLM.
- API contract stability: OpenAI (or similar) is committed to API contract stability.
200 good
responses are guaranteed and schema changes are versioned. - The hidden variable: a model update, such as GPT-5.4, introduces subtle changes:
- Tone or cadence: A slight change in the tone of the conversation could alter user engagement metrics.
- Presence of keywords: a critical keyword, which was previously always present in an abstract, is now occasionally omitted.
- Response length/structure: Minor variations in the output length or internal structure of a JSON object (even if schema-compliant) can break client-side parsing or rendering logic.
- Pace or latency: While the API itself remains "fast", the perceived latency of LLM response generation may change, causing interface timeouts or race conditions in dynamic UI elements waiting for a complete transmission.
These are not 500 errors. These are not even validation errors on the API gateway. The backend is green. The API contract is maintained. But their user experience is quietly degrading.
Architectural reality: the fragile dance of UI
This scenario exposes a critical flaw in traditional observability, which often operates under the premise that if the backend is healthy and the API returns 200 OK, the application is working as expected.
- API Monitoring Blind Spot: Confirms API availability and response structure, but not semantic integrity or consistency of content behavior. a
200 good
with subtly different content (e.g. a slightly less coherent summary of GPT-5.4) is indistinguishable from a perfect answer. - RUM Limitation: Real User Monitoring captures perceived performance and client-side errors, but has difficulty attributing a "slow" or "broken" user experience to a specific, subtle backend behavior change when no explicit JavaScript errors are generated. You see the symptom, not the root cause, in the backend semantic output.
- Fragility of static UI tests: Unit and integration tests for frontend components are written based on the expected results of LLM. When GPT-5.4 subtly changes those results, these tests pass (because the new result is still "valid" according to the scheme) or fail in ways that are difficult to diagnose as a model behavior problem rather than an interface error.
Imagine a dynamic chat interface where GPT-5.4's slightly different turn-taking mechanism causes a race condition in your UI's scrolling logic, or a content generation tool where a newly introduced nuance to the wording breaks a post-parsing regular expression. Your users see an "unpleasant" or "broken" experience, but their panels light up green.
Why This Matters: The Silent Trust Killer
This “silent behavior change” is not just an academic problem; It is a direct threat to your results:
- Erosion of user trust: Users perceive a degraded experience, even if they cannot explain why. This leads to frustration, reduced commitment, and ultimately, attrition.
- Increased support load: "The UI is not working", "The answers are not that good", "It used to work differently" - these become your new support tickets.